pyspark使用简单总结
分布式课程上涉及到了spark的使用,下面整理一点pyspark的概念和pyspark的操作方法。
Abstract:
Apache Spark是用Scala编程语言编写的。为了用Spark支持Python,Apache Spark社区发布了一个工具PySpark。使用PySpark,您也可以使用Python编程语言处理RDD。正是由于一个名为Py4j的库,他们才能实现这一目标。
Content:
SparkContext
SparkContext是任何spark功能的入口点。当我们运行任何Spark应用程序时,启动一个驱动程序,它具有main函数,并在此处启动SparkContext。然后,驱动程序在工作节点上的执行程序内运行操作。
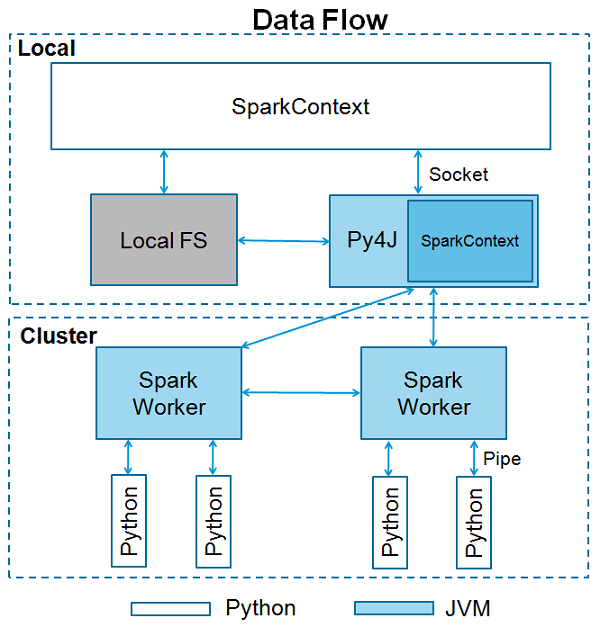
任何PySpark程序的前两行如下所示
1 | from pyspark import SparkContext |
SparkContext参数包括:
- Master - 它是连接到的集群的URL。
- appName - 您的工作名称。
- sparkHome - Spark安装目录。
- pyFiles - 要发送到集群并添加到PYTHONPATH的.zip或.py文件。
- environment - 工作节点环境变量。
- batchSize - 表示为单个Java对象的Python对象的数量。 设置1以禁用批处理,设置0以根据对象大小自动选择批处理大小,或设置为-1以使用无限批处理大小。
- serializer - RDD序列化器。
- Conf - L {SparkConf}的一个对象,用于设置所有Spark属性。
- gateway - 使用现有网关和JVM,否则初始化新JVM。
- JSC - JavaSparkContext实例。
- profiler_cls - 用于进行性能分析的一类自定义Profiler(默认为pyspark.profiler.BasicProfiler)。
注意:区分几个概念
- SparkContext is the entry gate of Apache Spark functionality and the most important step of any Spark driver application is to generate SparkContext which represents the connection to a Spark cluster, and can be used to create RDDs, accumulators and broadcast variables on that cluster.
- SparkSession is an entry point to underlying PySpark functionality in order to programmatically create PySpark RDD, DataFrame.
- SQLContext can be used create DataFrame , register DataFrame as tables, execute SQL over tables, cache tables, and read parquet files whereas SparkContext is backing this SQLContext. The SparkSession around which this SQLContext wraps.
- SparkConf offers configurations to run a Spark application on the local/cluster by supporting few configurations and parameters.
RDD
- RDD代表 Resilient Distributed Dataset,它们是在多个节点上运行和操作以在集群上进行并行处理的元素。
- 不可变元素,创建后无法进行修改
- 有容错能力,发生故障时会自动回复
- 主要操作
- Transformation:应用于RDD以创建新的RDD。 Filter,groupBy和map是转换的例子。
- Action:指示Spark执行计算并将结果发送回驱动程序。